The Hard Way For Spark to Read Data From S3
About four month ago(today is 2016.08.24), I had a try for Spark(1.6 version, latest version that time) to read data from S3 service in AWS Beijing Region. After an day’s experiment, I failed. The experience is recorded in this blog. It was written in Chinese. In short, Spark depreciate the support for read data from s3 in prebuild hadoop 2.6. So if you want to read data, you have to use a version of prebuild hadoop 2.4 which use jet3t library to access S3. The problem is that the jet3t version in Spark 1.6 is 0.7. It did not support AWS Signature Version 4 which is the only signature algorithm supported in AWS Beijing Region. And since that time I have very basic analysis needs and very small amount data, I stop trying to fix this.
And yesterday the new analysis problem brought me to consider solution again. As data growing & machine growing, it’s before more complicated now since I have to download all data from S3 to local if I still could not get problem solved. But the day four months ago is so desperate, and the issue I followed just continue sending me updated build pass or fail info but not telling me that it is merged in master. Anyway, I have to give a try.
First, today the latest version for Spark is 2.0. So I download the prebuild for hadoop 2.6. Not supersizingly, It still failed to deal with s3 scheme. But I found that the jet3t library it uses is 0.9.3 which is first version to support AWS Signature Version 4. Is that means problem could be solved by prebuild 2.4? After giving a try, I still failed. I get an 403 error from AWS which notifying me that I had the wrong access key which is strange, because the key I used I am pretty sure it is correct. So I try to access data from US region and it succeeded. So now the problem is why success in US and fail in China? I guess it’s the S3 endpoint problem because Beijing Region is someway special. Normally, you could use endpoint s3.amazonaws.com to all region. AWS would judge which region your bucket belongs and then to the correct address. But not in Beijing, you know, China… So I tried config jet3t.
After reading the configuration guide , I found a property that deserves a try: s3service.s3-endpoint. But how to make it effective? After searching, I found that jet3t library could read config file.But I even don’t know where I could put the config file… So I’am wondering if I could change the default config and recompile the library. After installing ant, I succeed in recompiling. But the read data is still failed. I have no idea what happened. I even use tcpdump to figure out why. And then I found that I make an stupid move that I replace the jet3t library in prebuild2.6 which do not use it at all…This version of Spark use the other two library to access S3: hadoop-aws2.7.2.jar and aws-java-sdk1.7.4.jar.(Another long story…)
I almost give up.
After cleaning my mind, I try to fix out which situation I am in. In short, if I want to use prebuild2.4, I have to config jet3t library. If I want to use prebuild2.6, I have to config aws-java-sdk. Both are java project while I have almost zero background in java knowledge. Time is limited, I have to decide which way to continue trying… After a thought, I choose to config aws-java-sdk since It is supported by AWS itself.
After searching Spark source code, I found there is no way I could config endpoint by env variable since code is like this
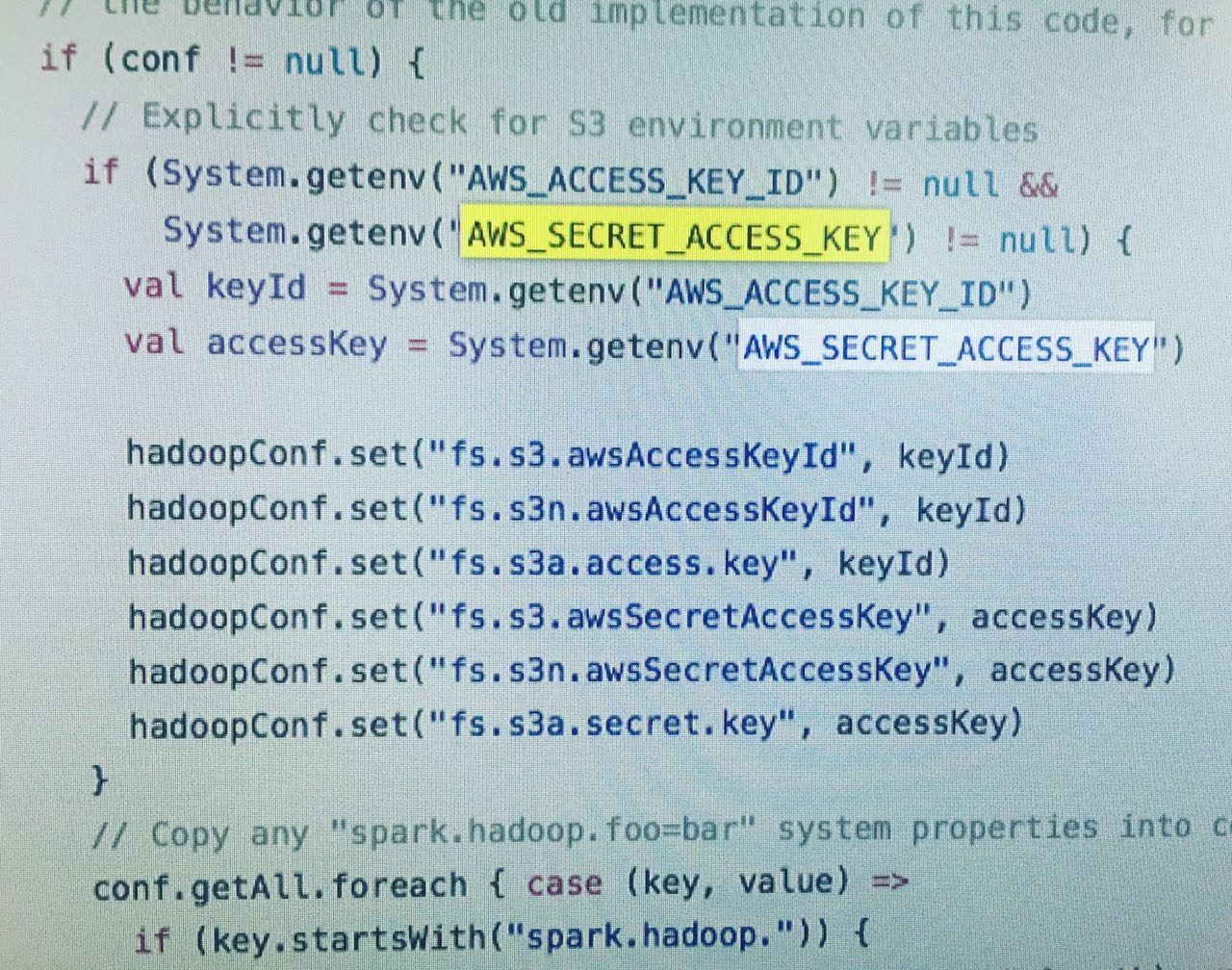
So I continue searching the code to find if there is another configure. And finally I found something that I could hardcode. After installing mvn , recompiling project and replace library. I succeed in reading data from S3 in Spark, in Beijing Region…
Conclusion:
-
For AWS user other than beijing region, you are fine. You could normally read data in different way: jet3t, aws-java-sdk..both hadoop2.4 and 2.6.
-
For AWS user in Beijing Region, you could place these two libraries in jars folder in Spark with prebuild2.6. And I think problem could be solved.
Another hard day in China…

blog comments powered by Disqus